PySpark: String to Array of String/Float in DataFrame
This is a byte sized tutorial on data manipulation in PySpark dataframes, specifically taking the case, when your required data is of array type but is stored as string.
I’ll show you how, you can convert a string to array using builtin functions and also how to retrieve array stored as string by writing simple User Defined Function (UDF).
We will discuss 4 cases discussed below with examples:
Case 1: “Karen” => [“Karen”]
Convert a string to string in an array. E.g. “Karen” to [“Karen”] and then lowercase it.
Case 2: ‘[“Karen”, “Penny”]’ => [“Karen”, “Penny”]
Convert array of strings stored as string back to array type. E.g. ‘[“Karen”, “Penny”]’ to [“Karen”, “Penny”]
Case 3: ‘[1.4, 2.256, 2.987]’ => [1.4, 2.256, 2.987]
This case is basically Case 2 with float values in array instead of string. E.g. ‘[1.4, 2.256, 2.987]’ to [1.4, 2.256, 2.987]
Case 4: ‘[“1.4”, “2.256”, “-3.45”]’ => [1.4, 2.256, -3.45]
When float values themselves are stored as strings. E.g. ‘[“1.4”, “2.256”, “-3.45”]’ to [1.4, 2.256, -3.45]
Case 3 and Case 4 are useful when you are using features like embeddings which get stored as string instead of array<float> or array<double>.
BONUS: We will see how to write simple python based UDF’s in PySpark as well!
Case 1 : “Karen” => [“Karen”]
Training time:
I wrote a UDF for text processing and it assumes input to be array of strings. Using this, I processed data and trained an ML model.

Test time:
During test time, however, the structure of data was just column of strings with each row containing a single string instead of array of strings.

In order to avoid writing a new UDF, we can simply convert string column as array of string and pass it to the UDF. A small demonstrative example is below.
1. First, lets create a data frame to work with.
2. Now let’s create a simple UDF which changes the string to lowercase.
3. Let’s apply this UDF to customers dataframe.
customers = customers.withColumn("new_name", convert_to_lower(F.col("name")))customers.show(truncate=False)
The result looks at follow:

Now, the data at test time is column of string instead of array of strings, as shown before.
new_customers = spark.createDataFrame(data=[["Karen"], ["Penny"], ["John"], ["Cosimo"]], schema=["name"])new_customers.show()+------+
| name|
+------+
| Karen|
| Penny|
| John|
|Cosimo|
+------+
Applying the same UDF will not give you desired results:
new_customers.withColumn("new_name", convert_to_lower(F.col("name"))).show()+------+------------------+
| name| new_name|
+------+------------------+
| Karen| [k, a, r, e, n]|
| Penny| [p, e, n, n, y]|
| John| [j, o, h, n]|
|Cosimo|[c, o, s, i, m, o]|
+------+------------------+
4. You can still use the same UDF by converting the string to array of string type using F.array() as:
new_customers.withColumn("new_name", convert_to_lower(F.array(F.col("name")))).show()+------+--------+
| name|new_name|
+------+--------+
| Karen| [karen]|
| Penny| [penny]|
| John| [john]|
|Cosimo|[cosimo]|
+------+--------+
Here is the complete code.
The final output looks as below:

Related topic: Learn how to create a simple UDF in PySpark
Now, we will do similar set of operations, so lets get right into it!
Case 2 : ‘[“Karen”, “Penny”]’ => [“Karen”, “Penny”]
Out test time data set in this case is as follows:
new_customers = spark.createDataFrame(data=[['["Karen", "Penny"]'], ['["Penny"]'], ['["Boris", "John"]'], ['["Cosimo"]']], schema=["name"])
new_customers.printSchema()
new_customers.show()
Note that the whole array is stored as string which you can see when you print schema (although it doesn’t exactly print like that with show()).
To parse it we will use json library from python and write a UDF which will retrieve the array from string. The output will be converting ‘[“Karen”, “Penny”]’ to [“Karen”, “Penny”].
Let’s apply this UDF and see the results
new_customers.withColumn("new_name", retrieve_array(F.col("name"))).show()
Again note that the actual transformation is from string to array of string as shown below:
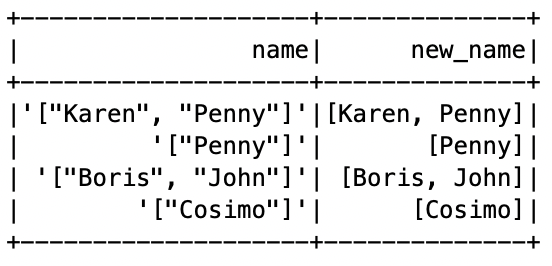
Now, lets apply the lower casing UDF also and finish case 2 in the code below:
Lets keep going and see the last 2 cases where we have float values as elements instead of string.

Case 3: ‘[1.4, 2.256, 2.987]’ => [1.4, 2.256, 2.987]
This case is same as Case 2 except that the elements are float value. Same as before we will write a UDF using json library of python. Lets see the data first,
df = spark.createDataFrame(data=[['[1.4, 2.256, 2.987]'], ['[45.56, 23.564, 2.987]'], ['[343.0, 1.23, 9.01]'], ['[5.4, 3.1, -1.23]'], ['[6.54, -89.1, 3.1]'], ['[4.0, 1.0, -0.56]'], ['[1.0, 4.5, 6.7]'], ['[45.4, 3.45, -0.98]']], schema=["embedding"])df.printSchema()
df.show(truncate=False)

From schema you can see that arrays are stored as string, although on printing it doesn’t look like that.
Lets directly jump into the code to see how to parse and retrieve the array of floats.
Case 4: ‘[“1.4”, “2.256”, “-3.45”]’ => [1.4, 2.256, -3.45]
This case is also quite common when array of floats (or doubles) is not only stored as string but each float element is also stored as array.
What will we do here now! If you have been following the post, you can guess => use UDF leveraging json library.
Let’s look at the data.
df = spark.createDataFrame(data=[['["1.4", "2.256", "-3.45"]'], ['["45.56", "23.564", "2.987"]'], ['["343.0", "1.23", "9.01"]'], ['["5.4", "3.1", "-3.1"]'], ['["6.54", "-3.1", "-3.1"]'], ['["4.0", "1.0", "9.4"]'], ['["1.0", "4.5", "6.7"]'], ['["45.4", "-3.1", "-0.98"]']], schema=["embedding"])df.printSchema()
df.show(truncate=False)

Our desired output is to convert each of the individual elements to float/double as well along with retrieving the array from string. The code for this is as follow:
Notice the usage of float for typecasting numbers stored as string back to float.
We made it through all the cases!! Yay!
